The data behind the popular movie database is available online. What might not be clear from this website is that we can use a copy data activity to connect to these tables from a pipeline. There is no need to manually download the files to your hard drive, you can refresh the data by running the pipeline.
You can build a demo dataset for presentations or other situations where you need non-sensitive, openly available data to demonstrate Fabric concepts such as medallion architecture and Direct Lake semantic models.
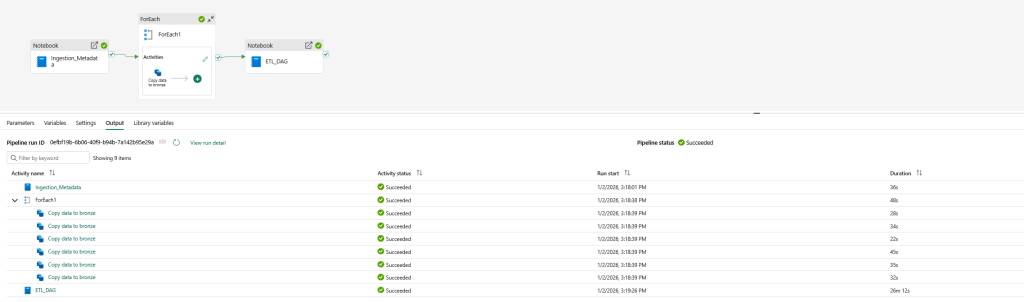
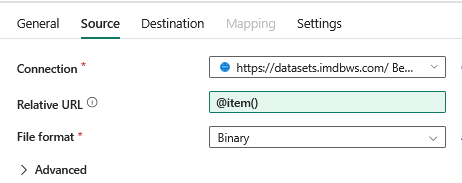
The heart of the pipeline is a copy activity that goes through a list of tables and loads them in a lakehouse. The relative URL is defined in a notebook called Ingestion_Metadata (first notebook on the left).
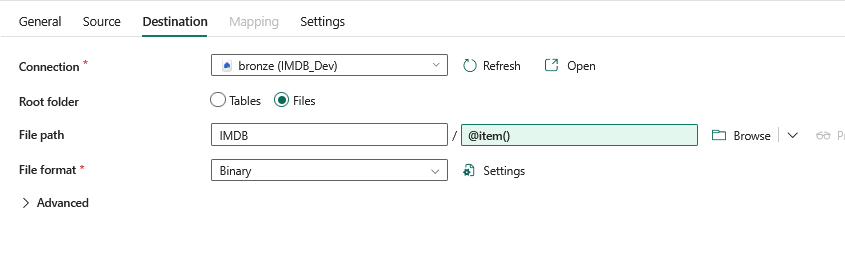
The destination tables are also in the metadata notebook. We are loading them into a lakehouse as files as they are in a zipped csv format called GZ.
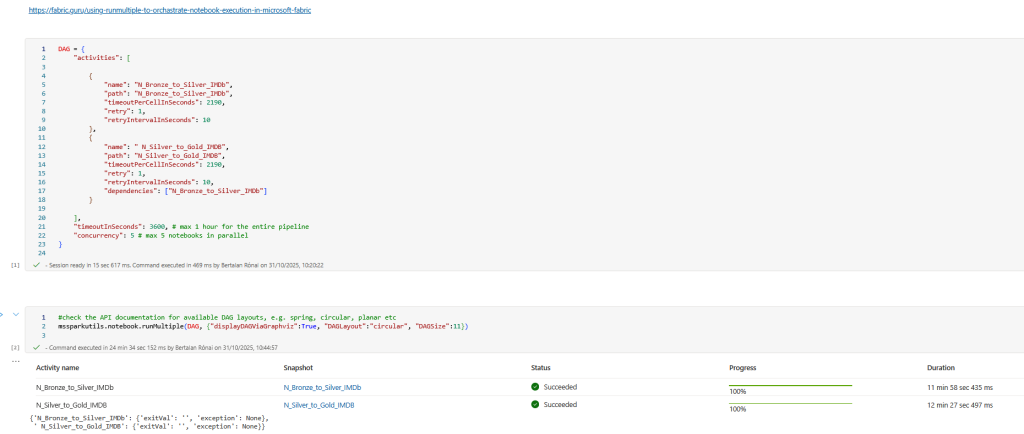
The last notebook runs a DAG process defined in a notebook that runs two notebooks, the first loads the tables from the files in the bronze layer to the silver lakehouse, the second notebook creates the tables in the gold lakehouse.
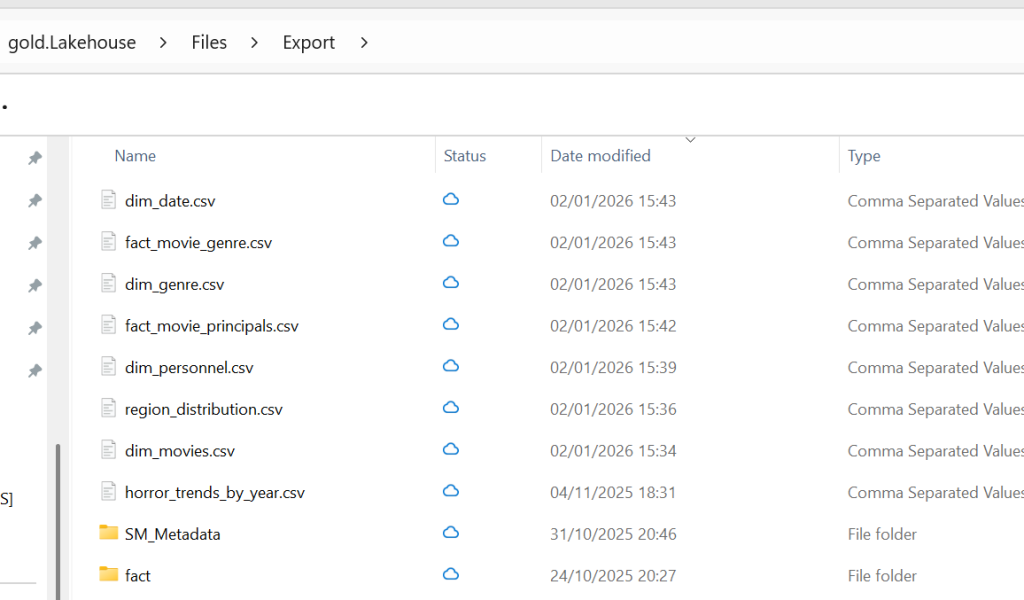
In the gold notebook after I loaded the tables to the gold lakehouse to prepare for a direct lake semantic model, I also wanted to export the tables as CSV in case I wanted to use this data outside of Fabric for example practicing data analysis w. python or building a local version of the model in import mode to test performance. The OneLake Explorer works the same way as OneDrive, it was very easy to sync the files from the lakehouse to my local machine.
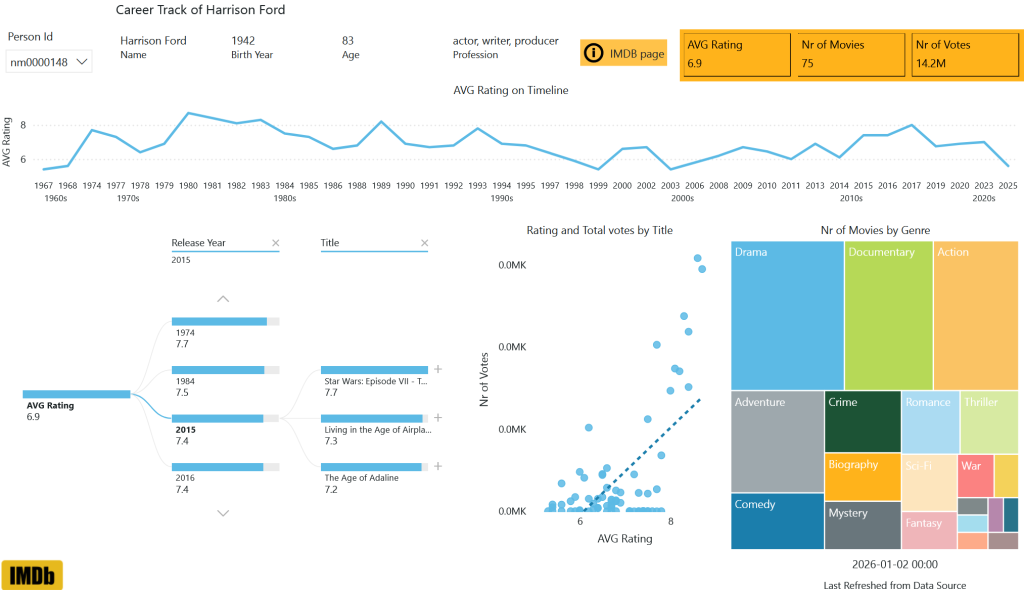
I'll share the link of the report here, let me add that I focused on the semantic model instead of the formatting. Usage: the best way to filter for an actor is using their id from their IMDB page, let's use Harrison Ford as an example, his id (nm0000148) is in the URL. If you used his name, you would find three actors. My post does not go into the details of how I created this report, nor am I sharing the PySpark notebooks for the ETL process. I am only recommending it for you to choose IMDB as a fun dataset to study and test Fabric features. Happy New Year!
Btw. if you want to be a part of a Fabric study community then join the Fabric Dojo!